

文丨財聯社
寫詩、編程、聊天互動……打著“AI聊天機器人”名頭的ChatGPT,集成了多種功能,也一躍成為史上月活用戶數增長最快的消費者應用。ChatGPT的爆火,也讓人們注意到了AI應用背后龐大的算力需求與挑戰。
中科曙光便表示,截止2月12日,曙光智算公司提供用于AI訓練與推理計算的試用資源,在開放使用后一周內已被搶注一空。通常情況下,這些計算資源要三個月左右才能被用戶注冊并使用。目前,曙光智算正協調多個計算中心,提供更多算力資源滿足用戶需求。
而在上周,浪潮信息也宣布推出AI算力服務產品,基于智算中心的算力基礎設施,客戶可申請AI算力免費試用。
實際上,以ChatGPT為首的生成式AI開發主要依托于大模型技術,這就離不開算力支撐。而在算力基建中,除了芯片之外,AI服務器、AIDC等專用數據中心建設也同樣必不可少。
就在2月13日,北京市宣布,將支持頭部企業打造對標ChatGPT的大模型。同日北京昇騰人工智能計算中心正式點亮,并與首批47家企業和科研單位簽約。該中心一期算力規模達100P,短期算力規模將達500P,遠期將達1000P,可為企業和科研單位等提供AI算力服務。

的確,AI對算力的需求已不能僅僅用“快速”來形容——據ChatGPT開發公司OpenAI 研究,2012-2018年,最大的AI訓練的算力消耗已增長30萬倍,平均每3個多月便翻倍,速度遠遠超過摩爾定律。
另據《2022-2023 中國人工智能計算力發展評估報告》,2022年我國智能算力規模已達268百億億次/秒(EFLOPS),超過通用算力規模。預計未來5年,中國智能算力規模年復合增長率將達52.3%。
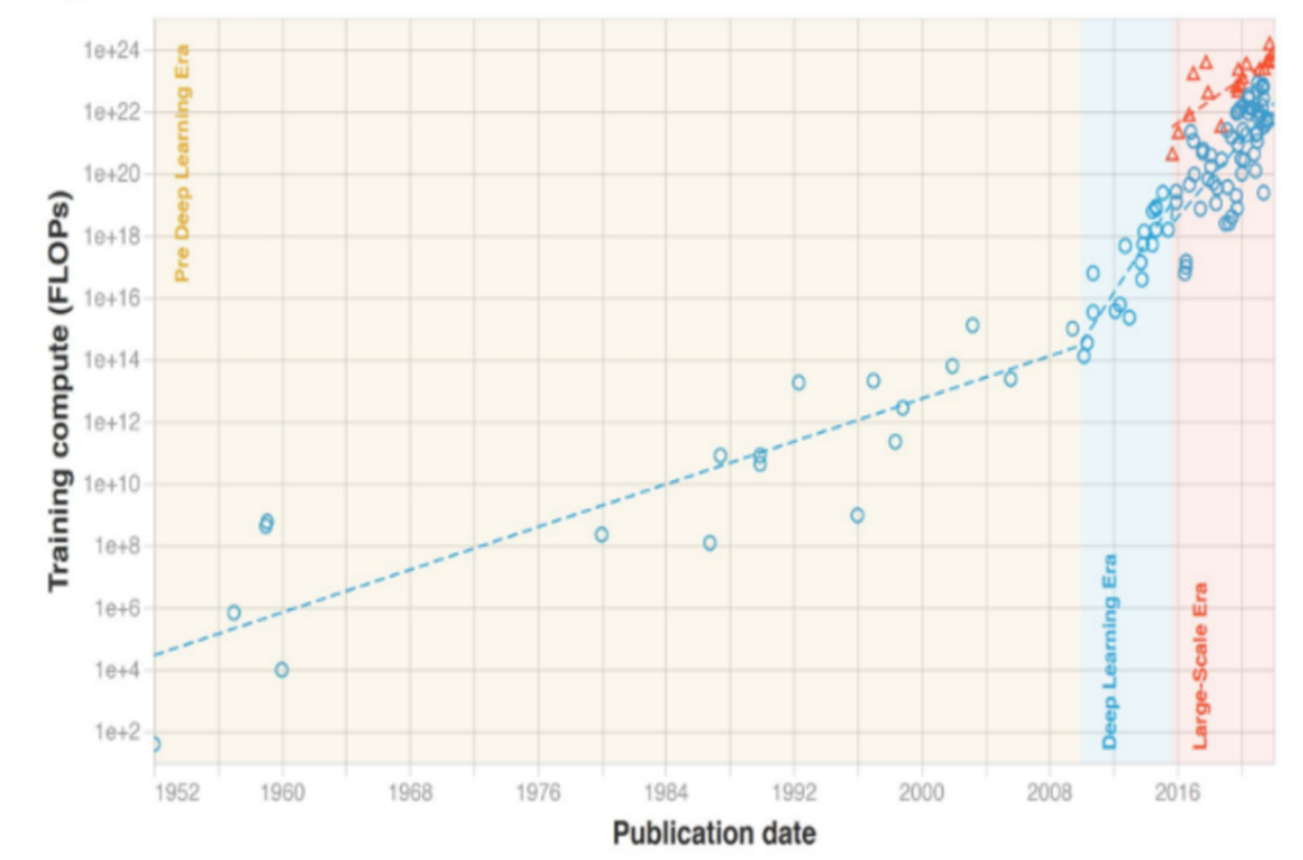
圖|人工智能算法計算量發展趨勢(來源:中信建投)
生成式AI的開發需要基于海量的自然語言或多模態數據集,對擁有巨大參數的超大規模模型進行訓練。要成功訓練出更大參數、更高精度、更高能力的大模型,不僅需要巨量的高性能AI算力進行支撐,還需要依托精心清洗獲得的高質量海量數據集,同時還需要有高效的系統平臺來保障長時間的模型訓練過程。
以OpenAI的GPT-3模型為例,其存儲知識的能力來源于1750億參數,訓練所需算力高達3640PFLOPS-day,單次訓練費用約460萬美元,而ChatGPT及未來GPT-4模型訓練成本將更高。當前,微軟Azure云計算中心為ChatGPT提供算力支撐,單次訓練成本超過千萬美元。
華泰證券2月13日報告也指出,以GPT模型為代表的AI大模型訓練,需要消耗大量算力資源,隨著國產大模型開發陸續進入預訓練階段,算力需求持續釋放或將帶動算力基礎設施產業迎來增長新周期。未來擁有更豐富算力資源的模型開發者,或將能夠訓練出更優秀的AI模型,算力霸權時代或將開啟。
正如上文提到的,算力基礎設施產業鏈主要可以分為三個環節:
(1)算力芯片:GPU采用數量眾多的計算單元和超長的流水線,架構更適合進行大吞吐量的AI并行計算,相關廠商包括景嘉微、寒武紀、海光信息、龍芯中科、中國長城等;
(2)服務器:ChatGPT模型訓練涉及大量向量及張量運算,AI服務器具備運算效率優勢,大模型訓練有望帶動AI服務器采購需求放量,相關廠商包括浪潮信息、中科曙光等;
(3)數據中心:IDC算力服務是承接AI計算需求的直接形式,隨著百度、京東等互聯網廠商相繼布局ChatGPT類似產品,核心城市IDC算力缺口或將加大,相關廠商有寶信軟件等。